Reinforcement Learning Taxonomy
Categorize Based on Available Information
- Imitation Learning (IL): Learn policy by cloning expert behavior. $$ \pi(\va|\vs)=\mathrm{IL}(\vtau^*)$$
- Reinforcement Learning (RL): Improve policy by maximizing total reward. $$ \pi(\va|\vs)=\mathrm{RL}(r)$$
- Inverse RL (IRL): Discover the objective of expert behavior. $$ r(\vs, \va)=\mathrm{IRL}(\vtau^*)$$
Under certain conditions, \(\mathrm{IL}(\vtau^*)=\mathrm{RL}(\mathrm{IRL}(\vtau^*))\).
| Method / Requirements | Interaction with Environment | Rewards | Trajectory Samples (from Any Policy) | Trajectory Samples from Expert Policy 1 |
|---|---|---|---|---|
| Online RL | (Required) | (Required) | (Collect Online) | - |
| Offline RL | - | (Required) | (Required) | - |
| Online IL | (Required) | - | (Collect Online) | (Required) |
| Offline IL | - | - | - | (Required) |
- Online IL/RL requires interaction with the environment.
- Offline IL/RL only requires trajectory samples.
- IL requires expert trajectory samples, while RL requires rewards.
Current literature often mixes the terms: Imitation Learning, Inverse RL, and Behavior Cloning, which actually focuses on different concepts.
- Imitation Learning is a general term for learning from expert behavior, which can be achieved through a variety of methods.
- To formally define the objective of IL, we need to utilize Inverse RL for quantifying suboptimality.
- One of the simplest IL method is Behavior Cloning, which simply maximizes the likelihood of expert actions. This target may output arbitrary outputs when encounters out-of-distribution states.
Categorize Based on Parameterization
For (Online) Reinforcement Learning:
Value-Based and Policy-Based RL, from Lecture 7, p.4 of UCL Course on RL by David Silver.
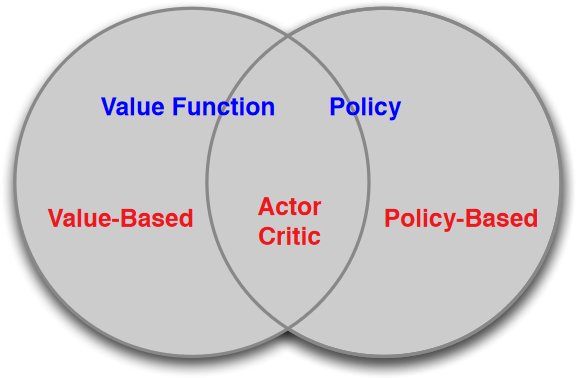
- Value-based Methods
- Learn value function \(Q(\vs,\va)\) based on the Bellman equations, and extract the policy \(\pi(\va|\vs)\) afterwards.
- E.g., DQN, Rainbow-DQN, IQN, etc.
- Policy-based Methods
- Directly optimize the policy \(\pi(\va|\vs)\) by gradient ascent based on the Policy Gradient Theorem.
- E.g., PPO, DDPG, TD3, SAC, etc.
- Actor-Critic Methods
- Training policy-based methods are inherently unstable due to the potential large variance of returns.
- Introducing a value-based critic to estimate the returns can effectively reduce variance.
- Actor: Policy-based method
- Critic: Value-based method
- Most policy-based methods are trained in Actor-Critic style.
-
Expert policy: a policy that performs well enough for a certain task. ↩