Magnetic Control of Tokamak Plasmas through Deep Reinforcement Learning
Goal: Tackle the tokamak magnetic control problem with DRL.
Contribution: The first work that achieves the desired plasma current, position and shape (for a few seconds) by learning to control several coils that are magnetically coupled to the plasma.
Background
- Nuclear Fusion vs. Nuclear Fission
- Nuclear Fission: Used in Nuclear power plant. $$ \ce{^235_92U + ^1_0n -> ^141_56Ba + ^92_36Kr + 3^1_0n + Energy}$$
- Nuclear Fusion: Used in the Sun. (Cannot be used in power plants yet.) $$ \ce{^3_1H + ^2_1H -> ^4_2He + ^1_0n + Energy}$$
- Why Nuclear Fusion?
- No long-lived radioactive waste.
- Sustainable source of energy.
- Challenges of Nuclear Fusion
- The reaction requires heating hydrogen gas to a plasma state (i.e., ionized gas) that becomes hotter than the core of the sun.
- Since the plasma consists of positively charged ions and negatively charged electrons, we can confine it using magnetic fields. In practice, the plasma can be contained in a tokamak, a doughnut-shaped vacuum surrounded by magnetic coils.
- Since the plasma is an electrical conductor, it is possible to heat the plasma by inducing a current through it.
- However, we need to ensure that the plasma never touches the wall of the vessel, which would result in heat loss and possibly damage.
- The main challenge is to control the tokamak's many magnetic coils and adjust the voltage on them thousands of times per second to achieves the desired plasma current, position and shape.
Concept
Overview, from Figure 1 of Degrave et al., 2022.
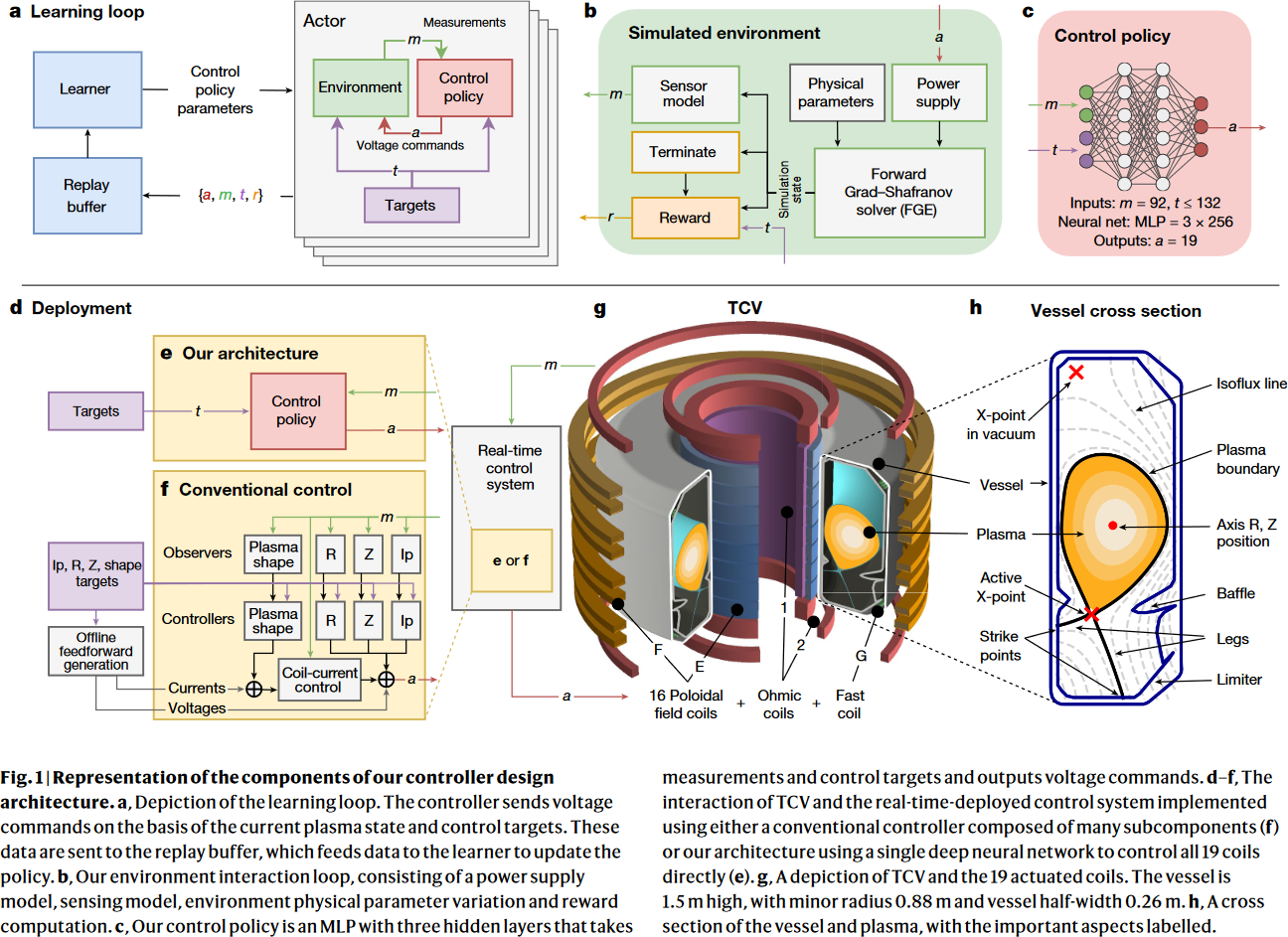
- Design the reward function (i.e., objective).
- Such as achieving a desired plasma current, position and shape.
- Penalizes the control policy for reaching undesired terminal states or states that are known to be poorly represented by the simulator.
- Apply DRL to learn a policy to achieve the objective by interacting with a simulator.
- Use a simulator that strikes a balance between physical fidelity and computational cost.
- Optimize with Maximum a Posteriori Policy Optimization (MPO).
- Actor (266,280 parameters): 4-layered MLP 1 (all with 256 latents) and an output layer. The network can fit in a L2 cache for real-time control.
- Critic (718,337 parameters): a LSTM layer followed by a 2-layered MLP (all with 256 latents) and an output layer.
- Train with 1 Learner on a TPU and 5,000 actors on CPUs for 1-3 days.
- Run the control policy in a zero-shot fashion on tokamak hardware in real time (10 kHz).
- At the beginning of an experiment, a traditional controller maintains the location of the plasma and total current.
- At a prespecified time, the control is switched (handovered) to the DRL control policy,
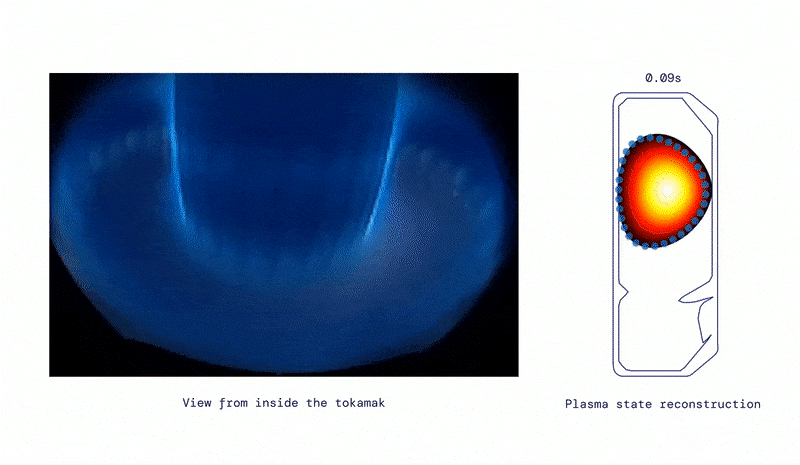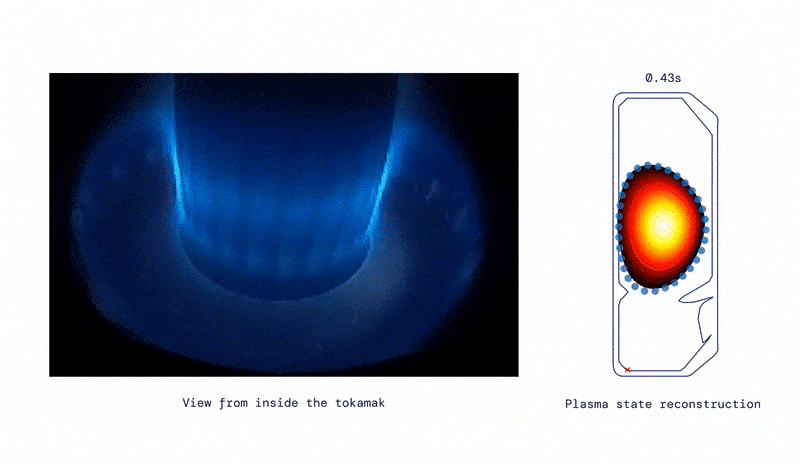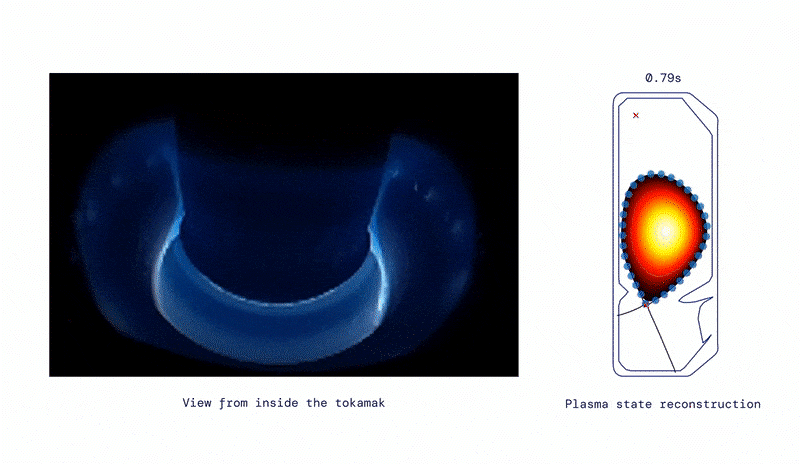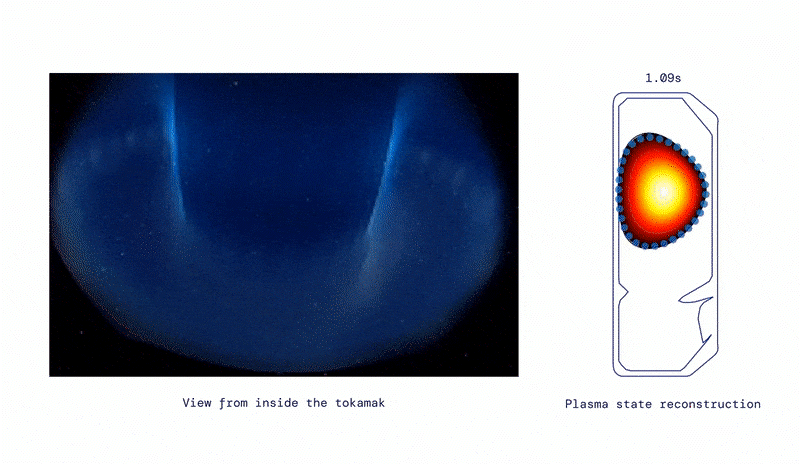
Inside view of the tokamak, from DeepMind Blog.
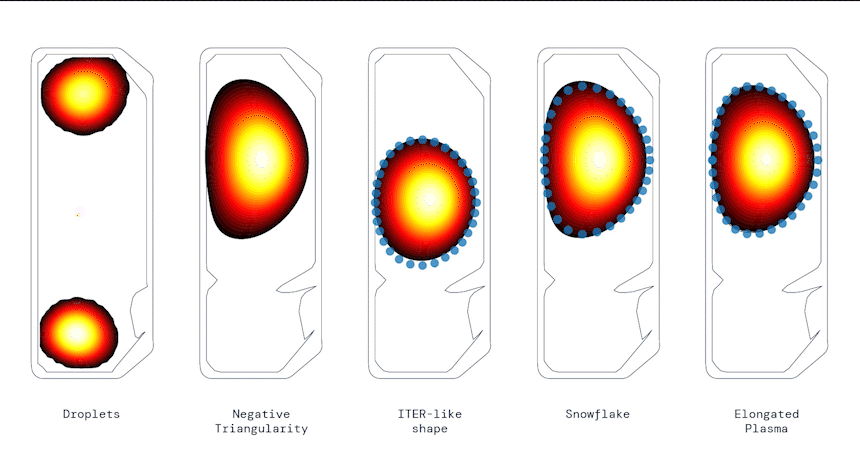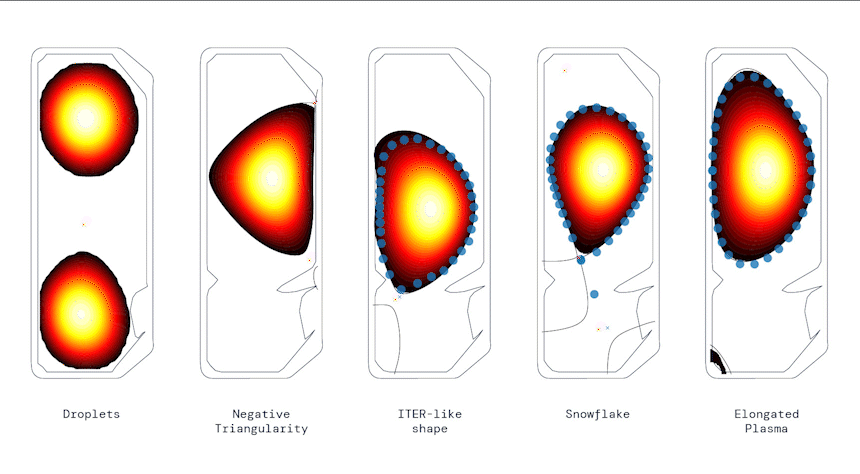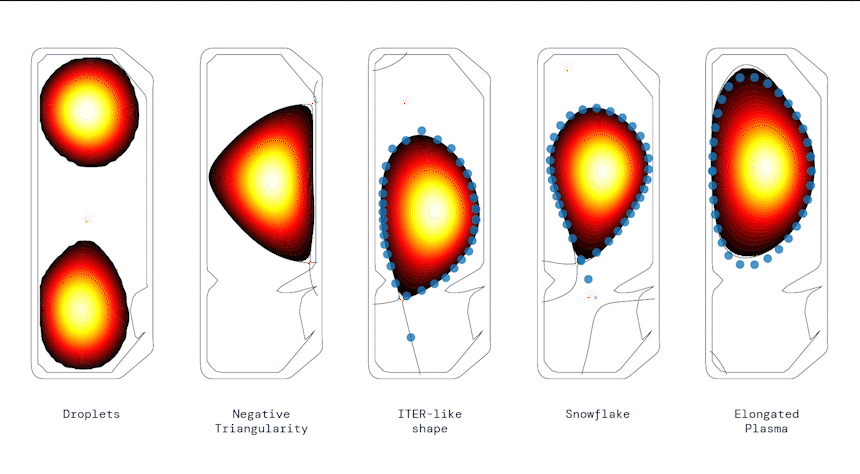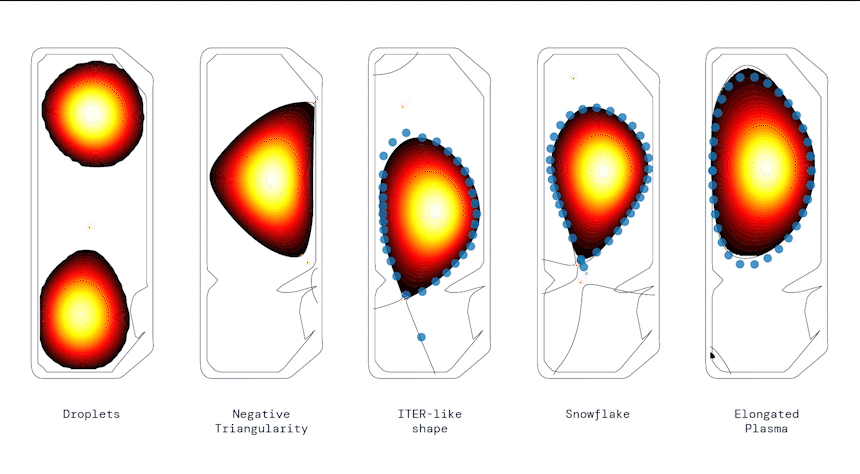
Producing a range of shapes, from DeepMind Blog.
Official Resources
- [Nature 2022] Magnetic control of tokamak plasmas through deep reinforcement learning [paper][blog] (citations: 257, 224, as of 2023-05-08)
-
I believe that there's a typo in Fig.1, where it mentioned that the policy network is a MLP with 3 hidden layers. In the Neural-network architecture section, it mentioned that the policy network is a MLP with 4 hidden layers. I think the latter is correct, since \(266,280 \approx (92+132) \cdot 256 + 256 \cdot 256 \cdot (4-1) + 256 \cdot (19 \cdot 2)\). ↩