Implicit Behavioral Cloning (Implicit BC)
Goal: Investigate the performance difference of implicit models (e.g., EBMs) and explicit models (e.g., mean square error, mixture density) on supervised policy learning.
Contribution: Observed that implicit models empirically performs better than explicit models, and provided some theoretical insight.
Concept
Implicit Model: \(\hat\va=\arg\min_{\va\in\mathcal{A}}{E_\theta(\vo,\va)}\), where \(E_\theta\) is a energy-based model (EBM) trained with InfoNCE loss.
- NCE vs. InfoNCE: InfoNCE deals with conditional distribution \(p(\vx|\vc)\) instead of \(p(\vx)\) in NCE.
Note that the argmin here can be solved by stochastic optimization.
Explicit Model: \(\hat\va=F_\theta(\vo)\).
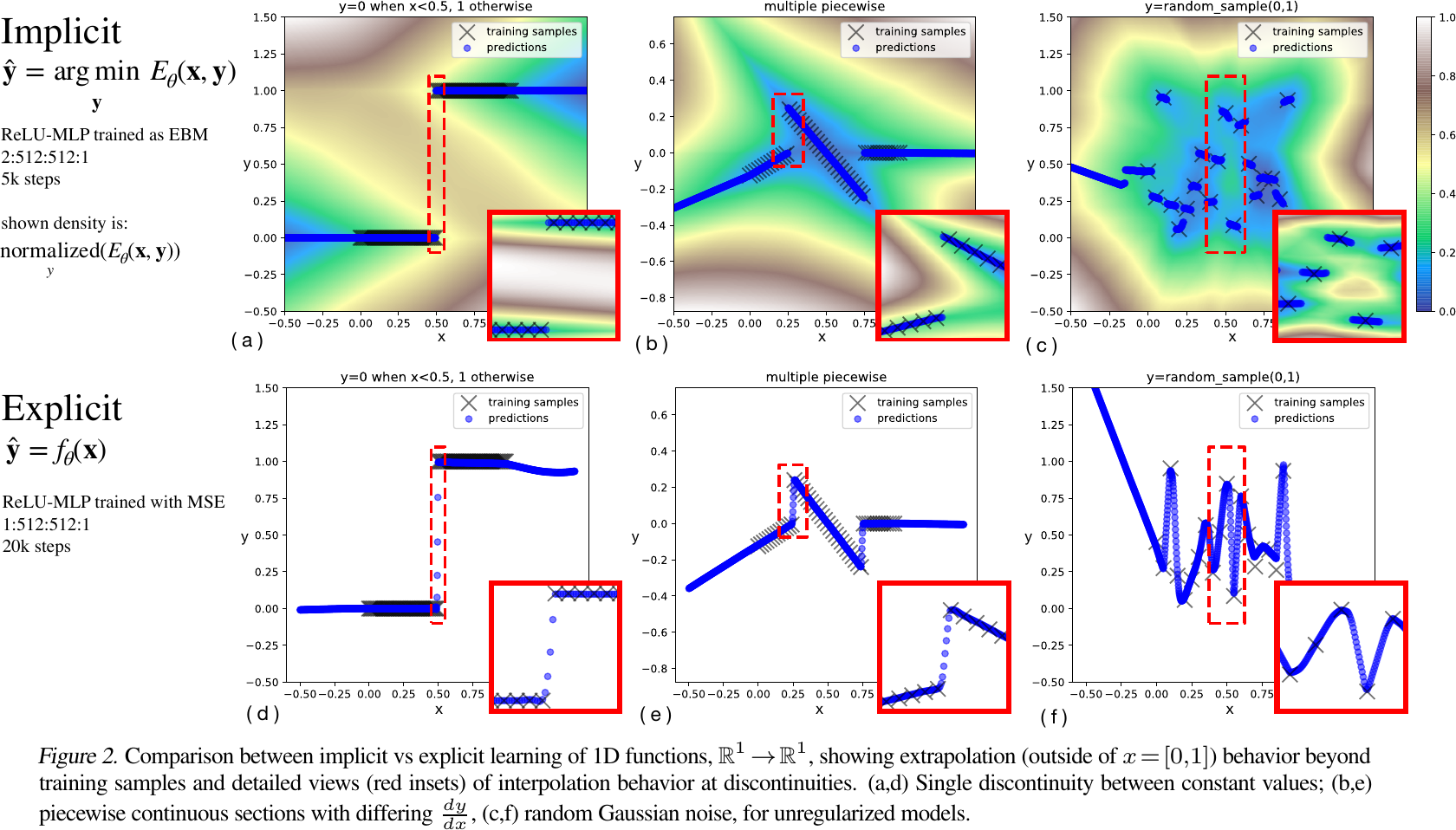
- Discontinuities
- Implicit models: approximate discontinuities sharply without introducing intermediate artifacts.
- Explicit models: tend to fit a continuous function to the data.
- Extrapolation
- Implicit models: tend to perform piecewise linear extrapolation.
- Explicit models: tend to perform linear extrapolation.
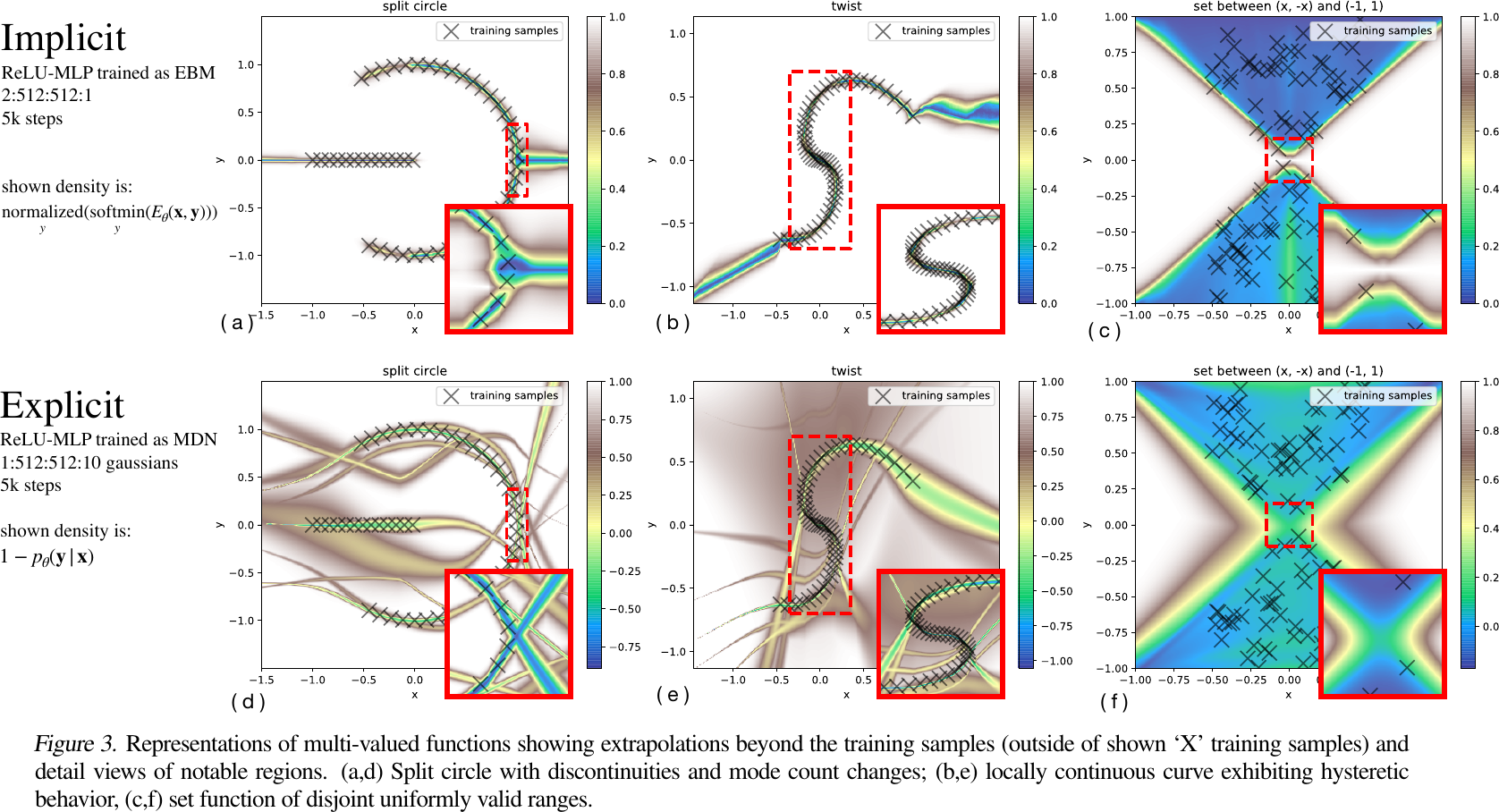
- Multi-valued Functions
- Implicit models: may output a set of values (using \(\arg\min\) as set-valued).
- Explicit models: output a single (optimal) value.
Experiments
Toy Tasks
Please note that the X in the following figures denote the ground truth data points.
Implicit models can model discontinuities easily:
Comparison between implicit vs explicit learning of 1D functions, from Figure 2 of Florence et al., 2022.
Representations of multi-valued functions, from Figure 3 of Florence et al., 2022.
Implicit models can learn to extrapolate easily:
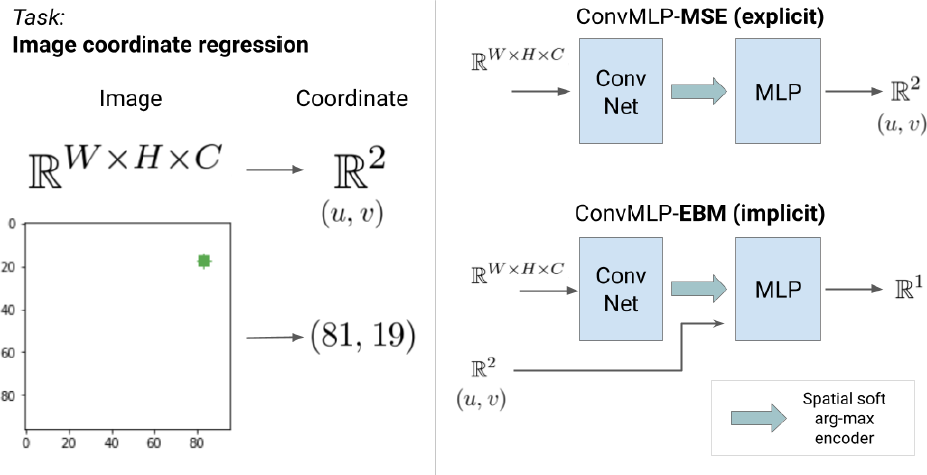
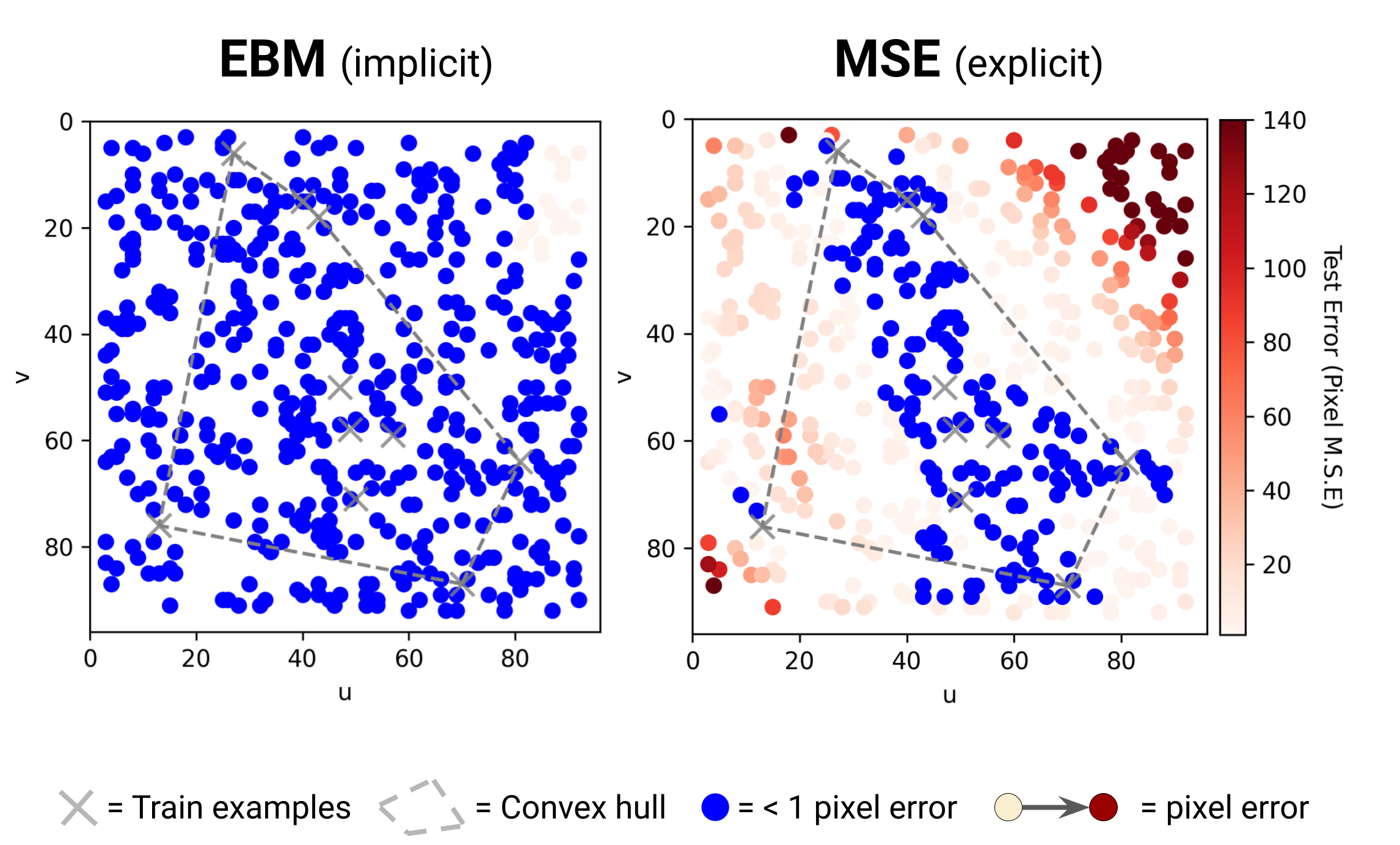
Implicit models can learn a multi-modal distribution easily:
Model a simple Heaviside step function, from authors' site.
High-dimensional Tasks
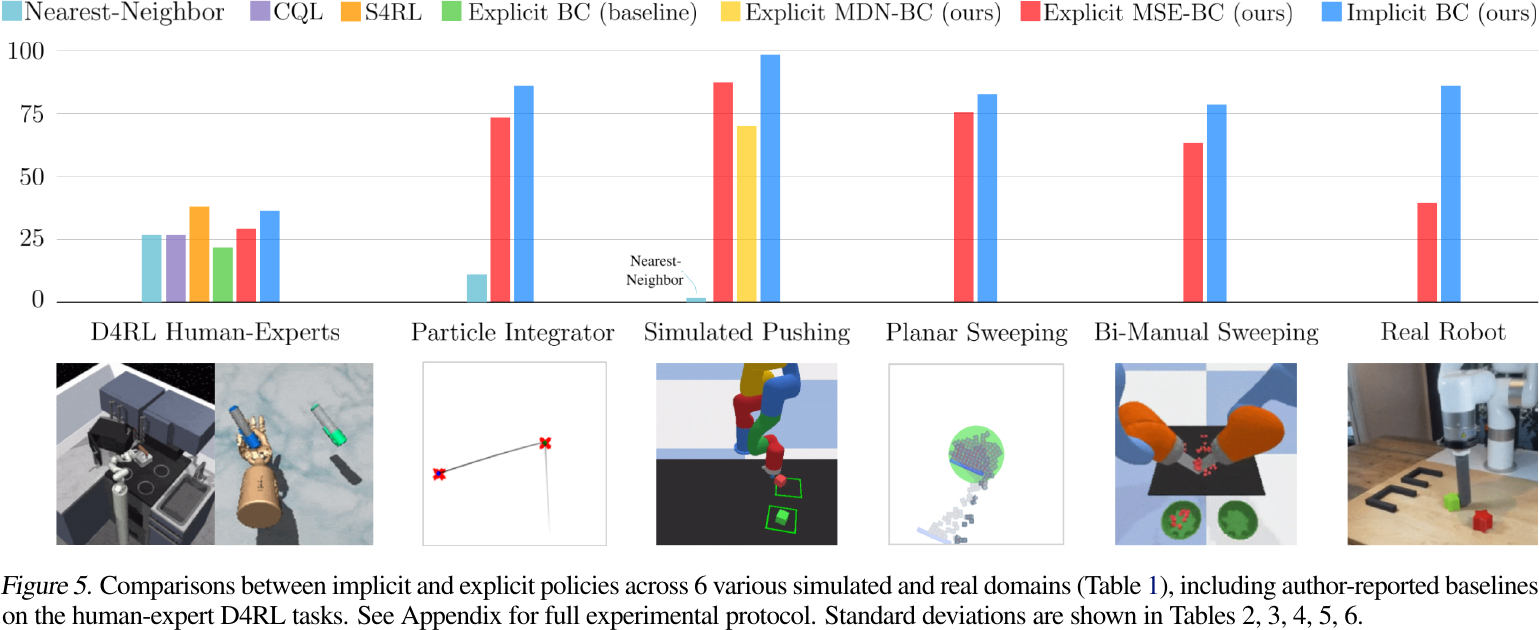
Performance:
from Figure 5 of Florence et al., 2022.
Benchmark characteristics:
from Table 1 of Florence et al., 2022.

Official Resources
- [CoRL 2022] Implicit Behavioral Cloning [arxiv][paper][code][site] (citations: 102, 97, as of 2023-04-28)