Generative Modeling Overview: a Probabilistic Perspective
Goals and Traits of Generative Models
- Density Estimation: pointwise evaluation of
- Data Generation: generating new samples
- Conditional Generation:
- Imputation:
- Conditional Generation:
- Training Target: the gradient of the loss
- Corresponding Metrics: (Forward) KL-divergence
- Corresponding Metrics: (Forward) KL-divergence
- Latents: whether latent variables
- Architecture: whether there are architectural restrictions on the neural network when modeling
Note
- Supporting fast pointwise evaluation of
- Tractable training target
- Likelihood (MLE) is often uncorrelated with the perceptual quality of the samples (images, sound, etc.) 1
Discussion
How can we parameterize
Considerations:
- Can we perform pointwise evaluation of
- (Required) Can we sample from
- (Required) Can we efficiently compute the gradient of the loss?
- Should we introduce a latent variable
- How can we design the model architecture to satisfy the restrictions?
Taxonomy of Generative Models
Overview of different types of generative models, from Fig.1 of What are Diffusion Models? by Lilian Weng, and from Fig.20.1 of Probabilistic Machine Learning: Advanced Topics.
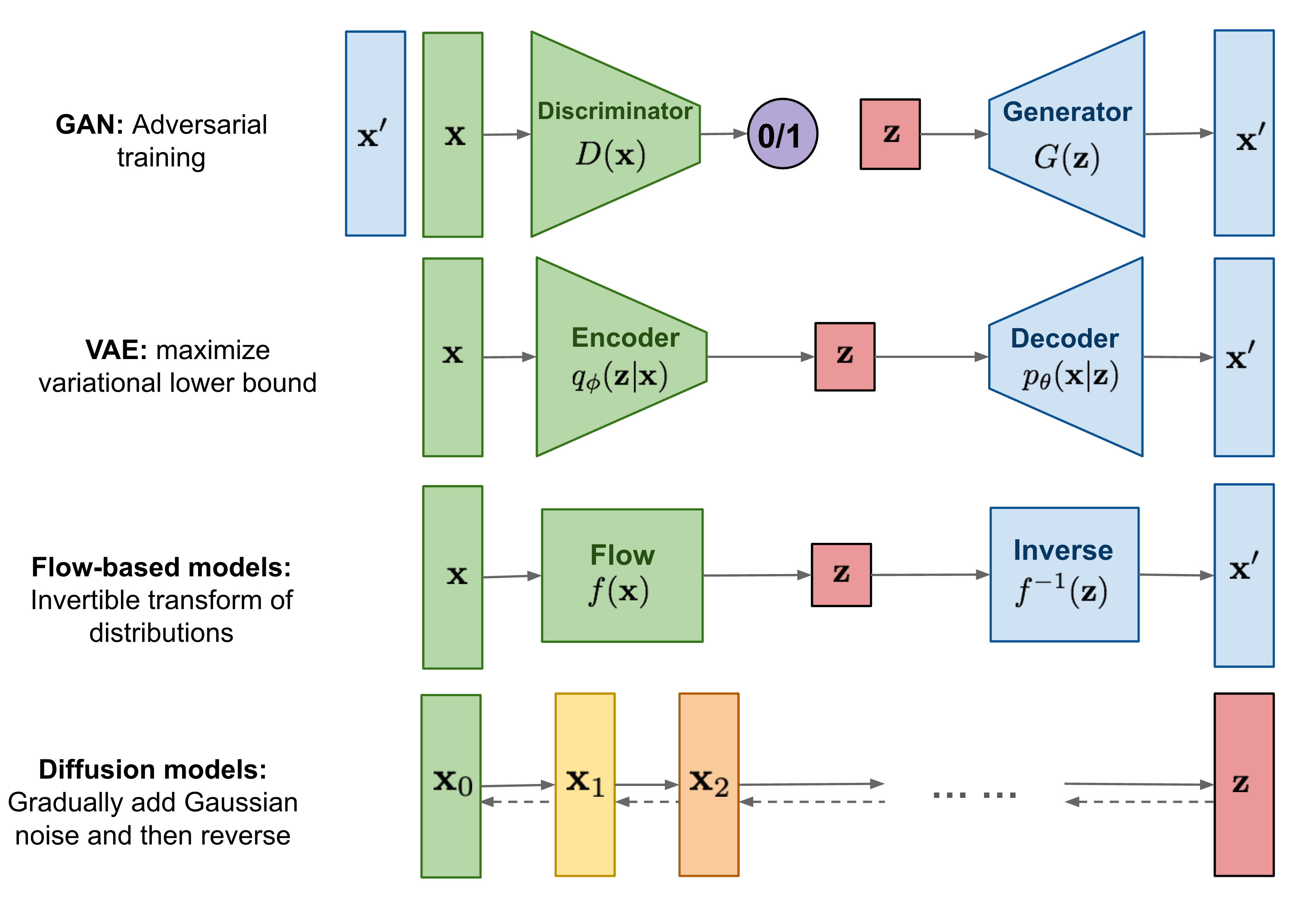
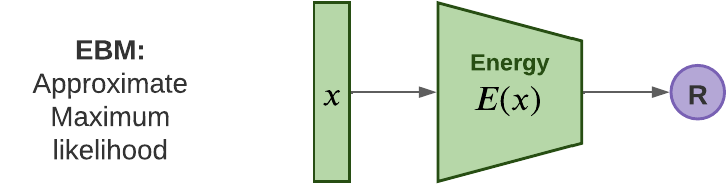

Characteristics of common kinds of generative model, modified from Table 20.1 of Probabilistic Machine Learning: Advanced Topics.
| Model | Density | Sampling | Training | Latents | Architecture |
|---|---|---|---|---|---|
| VAE | LB, fast | Fast | MLE-LB | Encoder-Decoder | |
| ARM | Exact, fast | Slow | MLE | None | Sequential |
| Flows | Exact, slow/fast | Slow | MLE | Invertible | |
| EBM | Approx, slow | Slow | MLE-Approx | Optional | Discriminative |
| DM | LB | Slow | MLE-LB | Encoder-Decoder | |
| GAN | N/A | Fast | Min-max | Generator-Discriminator |
Community Resources
- Probabilistic Machine Learning: Advanced Topics (i.e., probml-book2)
- Chapter 20: Generative models: an overview
-
See Section 20.4.1.3 "Likelihood can be hard to compute" from Probabilistic Machine Learning: Advanced Topics ↩